[Français]
Sponsor List
|
Scalable Real-time Search in P2P Networks
1. Background
In decentralized peer-to-peer (P2P) networks, real-time search is both a useful feature and a scalability nightmare.Real-time search differs from index-based search because the query is evaluated against the current state of the system, so it cannot return "stale" results (for data items that no longer exist or have been changed). Index-based searches, unless the index is updated in real-time (which is not practical for scalability reasons), always have the potential for returning stale results. As an example, search engines for the Web are index-based and not real-time. A query in Google for information about an event that happened today usually returns nothing of relevance, despite the fact that there are undoubtably several pages on the web that discuss the event. The Google News service, a frequently updated index of a Web subset, may have information about today's events, but it still lags behind the actual content of its chosen subset (and it entirely ignores the rest of the Web).
Gnutella was the first completely decentralized P2P network that came into wide use, and it featured real-time distributed searches. Ignoring the finer details, Gnutella search queries were essentially delivered to every node in the network using a "send to all neighbors" query forwarding mechanism. For a search to be exhaustive, every node in the network must process it, which is an obvious scalability problem. The number of new searches per second increases rather linearly with the network size (as each additional user adds additional searches), so the processing done by each node also would increase linearly with the network size. Gnutella included a mechanism for limiting the scope of a search (the number of nodes affected), and we will discuss that mechanism below. In practice, Gnutella's scope-limiting mechanism was not sufficient, so other solutions were used by Gnutella's successors.
Fasttrack, a proprietary network (the most [in]famous Fasttrack client is KaZaA), might be credited with the "supernode" or "ultrapeer" solution to the scalability problems associated with distributed search. An ultrapeer is a node that has more resources (for example, a faster CPU and better bandwidth) than most other nodes in the network. An ultrapeer uses these extra resources to gather information about the files being shared by the nodes around it in the network, and it builds an index out of this information. When an ultrapeer receives a search query, it does not "send to all neighbors", but instead forwards the search only to other ultrapeers that it knows about. Each ultrapeer searches its index for each search query and sends results back. Thus, only ultrapeers bear the load of processing search queries, and network traffic is greatly reduced. Many Gnutella clients added a similar ultrapeer feature, even though ultrapeers were not described explicitly as part of the original Gnutella protocol.
We should note that the ultrapeer solution does not offer real-time search, since it uses an index at each ultrapeer. Ultrapeer indices may be updated quite frequently, but they still have the potential for containing stale information. Real-time search is ideal, but networks have fallen back to index-based searches when real-time techniques failed to be scalable.
2. Time-to-live Counters
The main scope-limiting mechanism for Gnutella searches is a time-to-live (TTL) counter attached to each query message. This counter keeps track of how much farther the query should be routed in the network before being dropped. For example, TTLs often start with a value of 7. Each node that processes a query subtracts 1 from the TTL before passing the message on to its neighbors, and a message is dropped when its TTL reaches 0. If a TTL starts with a value of 7, it will travel 8 "hops" (through a chain of 8 neighbor connections) away from the sender before its counter reaches 0 and it is dropped. Of course, since messages are sent to all neighbors at each step, the path that they travel is more like a tree than a chain. If each node has 5 neighbors, and none of those neighbors overlap with the neighbors of other nodes in the tree (which is extremely unlikely), then a message that travels 8 hops would be processed by roughly 500,000 nodes.The first problem with the TTL scheme is that it does not limit the number of nodes affected by a search query in a precise way, since slight changes in the TTL drastically change the number of nodes that will process a query. For example, while a TTL of 7 will reach at most 500,000 nodes, a TTL of 6 will reach at most 100,000 nodes. These limits are easiest to present in a table (which assumes that each node has 5 neighbors):
| TTL | Max. Nodes Reached |
| 0 | 5 |
| 1 | 30 |
| 2 | 155 |
| 3 | 780 |
| 4 | 3,905 |
| 5 | 19,530 |
| 6 | 97,655 |
| 7 | 488,280 |
| 8 | 2,441,405 |
| 9 | 12,207,030 |
The second problem with TTLs is that, by default, all search queries the same distance in the network. An extremely general search, like "mp3," will likely generate many results from most nodes that process the query. Let us assume that each node generates only 10 results for an "mp3" search. If the search is sent with a TTL of 7, the search will reach 500,000 nodes (extreme case), which means that 5,000,000 results will be generated and routed back to the node that requested the search. Stepping back from the extreme case, we can still imagine that, in practice, a search for "mp3" will generate a million results if it travels 8 hops in the network, and a million is a big number. The node that sent the search request cannot handle receiving hundreds of thousands of result messages all at once (network and CPU limits), nor can it handle displaying and scrolling through millions of results (limits of graphical user interfaces).
On the other hand, a search for something rare may not produce results at all if the search only reaches 500,000 nodes. We might imagine that only one node out of every million nodes has a desired data item, so a starting TTL of 7 would be unlikely to find it.
A search for "mp3" would certainly return a sufficient number of results if it started with a TTL of 4 or even 3, so why not use small TTLs for searches that are likely to generate lots of results? The problem is that the TTL on a message is set by that message's sender. To automatically trim back TTLs, node software would need to process a user's search string and guess whether it will generate lots of results---this is probably impossible in practice, especially in the face of chaining cultural trends. We could leave specifying a starting TTL up to the user (a drop-down list of TTL choices next to the "Search" button), but we cannot ensure that users will reliably select appropriate TTLs or that they will understand the network load implications of inappropriately high TTLs.
Another possible solution is to start off with a low TTL and resend the search with a higher TTL if no results are generated by the fist search. Several Gnutella clients implement this solution in an automatic way, but there are two problems with this approach. First, responsiveness is reduced, since the search process takes longer (the node waits for results to come back from the low-TTL search before retrying). Second, search query traffic is increased for the nearby nodes that are hit by both queries.
3. The Goal
If we step back from the problem, we can think about what scope-limiting mechanisms like TTLs are trying to achieve. A distributed network has a limited set of resources, which include the network bandwidth and CPU processing power at each node. Users share this collective set of resources when their nodes are part of the network. When a user sends a search request into the network, that request consumes a portion of the network's collective resources. Scope-limiting mechanisms are designed to limit the resources consumed by a particular search query and thus limit the share of network resources that each user can consume.4. What TTLs Miss
The TTL mechanism limits how far a query travels in the network, effectively limiting the number of nodes that process a query. So, only a subset of the nodes see each query. If we assume that the query start points are distributed at random, then each node will only see a subset of the queries. Thus, CPU processing at each node is limited by TTLs. In other words, if the network-wide starting TTLs were reduced from 7 to 5, we would expect the CPU load at each node to be reduced as a result. In addition, since each query message consumes some network bandwidth at each node that receives and forwards it, we can see that TTLs also limit the network bandwidth used by each node.However, CPU processing and search query bandwidth are not the only resources consumed by the search process.
4.1 Search Result Bandwidth
What about search result messages that are routed back to the search's sender? If no results are generated, then the starting TTL of a search can be used to directly control the CPU and bandwidth resources consumed by a search. However, we saw before how different searches can generate vastly different numbers of results. CPU load is primarily due to processing search queries (searching the local file list for matches), so to simplify the discussion, we will ignore the CPU load caused by simply forwarding and routing messages, including search results. Bandwidth, on the other hand, is consumed by all messages, both forwarded and routed, and it is proportional to the size of the messages. Search result messages, in general, are much larger than search query messages, so they consume much more bandwidth at each node that processes them.In fact, a message with as few as 10 results can be 100 times bigger than the corresponding search query, and many queries generate many more than 10 results at each node. Of course, search queries are broadcasted, which means that they can hit each node more than once (nodes drop duplicates, but duplicates still consume inbound bandwidth). On the other hand, search results are routed, which means that they will hit each node at most once. Given these factors, which consumes more bandwidth, a broadcast search query, or the corresponding routed search results?
Since nodes drop duplicate search queries, the number of duplicates received by a node is limited by the number of neighbors that it has in the network (each neighbor will send a given message to a node at most once). To be fair, we can assume that each node has 10 neighbors (a lot of neighbors, in practice), so in the worst case, each node can receive 10 duplicates of each search query. If a search query consumes 1 unit of bandwidth to be sent or received, then a modestly-sized search results message would consumes 100 units. In the worst case, a single search query will consume at most 11 units of bandwidth at each node: 1 for receiving, 1 for sending, and 9 for receiving duplicates (which are dropped). A search results message, with a size of 100 units, will consume 100 bandwidth units at the node that generated the results and 200 bandwidth units for each node in the routing chain (to receive and then send the results onward).
A search query with a starting TTL of 7 will, in the worst case, reach about 500,000 nodes (in a network where each node has 5 neighbors that do not overlap with other nodes' neighbors), and thus will consume a total of 5,500,000 units of bandwidth (11 units at each node hit). Assume only 10% of these nodes (50,000) send back results, and assume that each result is 100 units in size. If the results travel an average of 4 hops each, then each result message will consume 700 units of bandwidth (100 at the result sender, 200 at each of the 3 intermediary nodes, and ignoring bandwidth consumed at the node that initiated the search). The results in this case would consume 35,000,000 units of bandwidth, more than 6 times more bandwidth than the search query. But was our assumption of a 10% node hit rate fair? What about our assumption of an average result route of 4 hops? These tables show more general results:
Search TTL of 7; Results traveling an average of 4 hops
| Percent of Hit Nodes Producing Results | Worst Case Total Search Query Bandwidth | Corresponding Total Search Result Bandwidth |
| 50% | 5,500,000 | 175,000,000 |
| 10% | 5,500,000 | 35,000,000 |
| 5% | 5,500,000 | 17,500,000 |
| 2% | 5,500,000 | 7,000,000 |
| 1% | 5,500,000 | 3,500,000 |
Bandwidth used by a 1-unit search and 100-unit results
Search TTL of 7; Results traveling an average of 7 hops
| Percent of Hit Nodes Producing Results | Worst Case Total Search Query Bandwidth | Corresponding Total Search Result Bandwidth |
| 50% | 5,500,000 | 325,000,000 |
| 10% | 5,500,000 | 65,000,000 |
| 5% | 5,500,000 | 32,500,000 |
| 2% | 5,500,000 | 13,000,000 |
| 1% | 5,500,000 | 6,500,000 |
| 0.5% | 5,500,000 | 3,250,000 |
In the 7-hop result distance table, we can see that bandwidth consumed by search results is greater than that consumed by the query, even with a 1% node hit rate. For wildcard-style searches (like "mp3"), we can assume that the node hit rate is much larger than 1%.
Fixed starting TTLs focus on limiting the impact of search queries (both CPU and bandwidth impacts), but these tables show that search results can consume far more bandwidth than queries. In addition, the bandwidth impact of the results can vary greatly from query-to-query (depending on how general the query is), and fixed starting TTLs do not address this variance at all.
For most nodes, bandwidth is far more limited than CPU processing power. Even relatively slow CPUs can generate thousands more bytes per second than the average broadband upstream connection can handle. Plus, the CPU load induced by each search query is relative to the size of a given node's shared data list. Nodes can limit their CPU load by reducing the number of data items they are sharing.
4.2 All Hops are Not Equal
Returning for a moment to the CPU and bandwidth resources consumed by the queries themselves, we can examine an additional flaw in the TTL scheme.In the above discussion, we have assumed a uniform branching factor of 5. In other words, when a message enters a node through one of its neighbors, it leave the node down 5 fresh network paths. The node may have more than 5 neighbors, but some of them may have already received the message through other neighbors, so they drop any duplicate messages. With this assumption, along with a starting TTL of 7, the paths traveled by the message in the network can be represented by a tree:
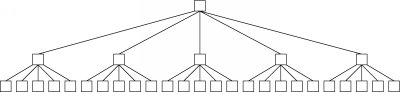
This tree only shows the first 2 hops (with a TTL of 7, the final tree would contain 8 hops), but we have already reached 30 nodes. Each hop, according to our assumption, goes through a 5-degree branch, effectively starting 5 new subtrees. After all 8 hops have been completed, we will have reached roughly 500,000 nodes, as discussed earlier.
Of course, if our branching factor is not uniform at every hop, the resulting number of nodes reached can vary dramatically. For example, suppose a message goes through several 1-degree branches and then go through a 5-degree branch on its last hop, like this:
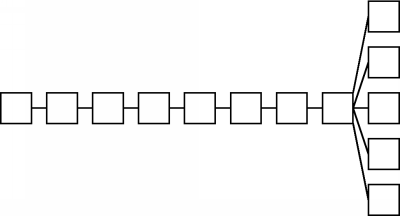
This tree shows all of the hops that the message takes (starting with a TTL of 7 and until that TTL reaches 0). The message only reaches a total of 12 nodes.
With TTL counters, a hop is a hop, regardless of what degree branch it passes through. This simplification hinders how accurately a TTL limit can control the network load generated by a message.
5. More Accurate Measures for Resource Usage
In the previous section, we showed how the TTL limit does not give us accurate control over the resources consumed by a given search query. We can now consider other factors that might give us better limits.5.1 Limiting the Number of Results Generated
TTLs limit the number of nodes hit by a search query, which indirectly has some effect on the number of results generated. We have seen that result messages can clearly have a bigger bandwidth impact, so why not try to limit the number of results generated explicitly? In fact, a mechanism that effectively limits results instead of the number of nodes hit will both improve performance and improve functionality. After all, if a search query generates very few results, we would want it to hit more nodes, since that increases the chances that we will find what we are looking for. On the other hand, if a search query generates lots of results, we would not want it to travel as far, since we cannot deal with huge results lists very well as end users.By limiting the number of results generated, we can better limit how much use (or utility) each user can get out of the network by sending a search query. After all, search queries are only useful when they generate results, so we can best measure the utility of a given query by how many results it generates.
5.2 Accounting for the Branching Factor
Messages that pass through high-degree branches result in more resource consumption than messages that pass through low-degree branches. Thus, we should not just limit the number of hops that a message takes, but also account for the branching factor at each hop.5.3 Hops are Still Important
Keep in mind that we cannot ignore the hop count entirely and focus only on the number of results generated, since searches that generate no results (or results only down certain paths) would then be allowed to flood the entire network. Also, we must have a deterministic factor as part of our limit, and a hop-based measure is deterministic. Any probabilistic limiting mechanism is not compatible with branching paths in the a network: the branching factor causes the number of distinct paths to grow exponentially as a message gets farther from its source, essentially outweighing any mechanism that drops a message probabilistically at each hop.6. Properties of a Limiting Mechanism
With the preceding discussion in mind, we can now present a list of desirable properties that a search-limiting mechanism should have.- Single Integer Representation: the measure used by the limiting mechanism must be representable as a single integer that can be attached to a query. This ensures backwards-compatibility with TTL-based networks.
- Distributed Enforcement: the limit must be enforced in a distributed fashion by each node that processes a query. The sender of a query should not be able to increase the resource consumption of that query.
- Total Limit: all queries must be dropped eventually, and it should be impossible for a message to take an unlimited number of hops in the network.
- Deterministic: the decision for a node to drop a message must be made in a deterministic (non-probabilistic) manner.
- Account for Branching: the limit must take the branching factor at each hop into account.
- Account for Results: the limit must take the number of results generated by a query into account.
7. Utility Counters
Utility counters (UCs) are a simple mechanism that limits how far a query travels based on both the branching factor at each query hop and the number of results generated by the query. UCs have all of the properties described in the previous section, and they can completely replace TTLs in any P2P network that supports distributed search. UCs are used instead of TTLs in the MUTE File Sharing network.Each search query is tagged with a UC, and the UC starts out at 0. Search queries are forwarded with a "send to all neighbors" scheme just like they are in a TTL network, and the UC on a query is modified before forwarding in two different ways. First, if a node generates results for a given query, the node adds the number of results generated to the UC before forwarding the query. Second, the number of neighbors that a node plans to forward the query to is added to the UC. For example, if a node receives a query with a UC of 25, and it generates 10 results, then it first increases the UC to 35. If it plans to forward the query to 6 of its neighbors, it increases the UC again to 41, and then it forwards a query to its neighbors.
Nodes in a UC-based network each enforce a UC limit: if a search query's UC hits this limit, it is dropped without being forwarded to neighbors. For example, if the UC limit is 100, a node that drops a query can surmise one of the following: that the query has generated at least 100 results, that the query has passed through hops with a total branching factor of 100, or that the query has reached the limit through a combination of both factors (for example, that it has generated 75 results and has passed through hops with a total branching factor of 25). Thus, the UC limit approximates an accurate control over how much utility a search sender can glean from the network with a single query.
7.1 Parameterized Utility Counters
In the above examples, we presented a scheme for UC updates without parameters for clarity. In practice, we use the following parameterized formula for updating UCs:Alpha and beta are parameters that control how much weight results and branching factors carry in a UC. Gamma controls how much weight the hop count carries, and it is provided so that UCs can emulate standard TTLs.
The parameters used in the above examples are [alpha=1; beta=1; gamma=0]. TTLs can be emulated with [alpha=0; beta=0; gamma=1].
8. Extended Utility Counters
Because of the requirement of a single integer representation for our utility measure, UCs have a somewhat limited accuracy for measuring resource usage. For example, UCs count all results as equal. In fact, results that are generated farther away from the query sender consume more resources, since they must be routed back to the sender over several hops, using bandwidth at each node that they pass through. Bandwidth usage for a result varies linearly with the number of hops the result must travel through to reach the sender. If we were allowed a dual-integer representation, we could take result distance into account by tracking both a UC and a raw hop count. With this extended representation, both the UC and the hop count would start at 0, and the hop count would be incremented at each hop. Our formula for the UC contribution of generated results would then contain:Another detail that our simple UCs miss is the effect of tree depth on the impact of branching factors. High-degree branches that are encountered close to the query sender have a larger impact than high-degree branches encountered toward the end of the query's life. Earlier, we showed the tree for a query that traveled through several 1-degree branches and then went through a 5-degree branch on its last hop---the query impacted a total of 12 nodes. The following tree results from a query that does just the opposite, hitting a 5-degree branch followed by several 1-degree branches:

This query reaches 40 nodes. Notice the final UC is 12 in both the 12-node and the 40-node cases, so single-integer UCs obviously cannot account for the effect of high-degree branches being encountered at different points in a query's life.
To deal with this effect, we can adjust the weight of the forwardNeighborCount based on the current hop count: the weight should decrease as the hop count increases. On way to do this would be with the following formula:
Thus, at hop 0, forwardNeighborCount is squared, and the power that forwardNeighborCount is taken to approaches 1 as hopCount increases. With this formula, the final UC in the 12-node case is 12, and the final UC in the 40-node case is 32, which is certainly an improvement. Other formulas are possible, though there is no way to accurately compute the total number of nodes impacted by a search using only in the information locally available to a particular node.
The final formula for updating extended UCs is as follows:
| newUC = oldUC | + alpha * localResultCount * hopCount |
| + beta * forwardNeighborCount^( 1 + 1/(1 + hopCount) ) | |
| + gamma |
9. Ensuring Search Sender Anonymity
Given the branching factors inherent in a "send to all neighbors" flooding scheme, a deterministic limiting mechanism is necessary. However, a deterministic mechanism is not compatible with the goal of sender anonymity. For example, receiving a query with a UC of 0 from your neighbor means that your neighbor sent that query.To deal with this issue in MUTE, we use a hybrid approach for search flooding. We can think of the search flood as a tree, with the search sender as the root. The primary reason that true probabilistic limiting schemes do not work with branching message paths is that independent probability calculations are being made by each node at a given level of the tree. Because the number of nodes at given level grows exponentially as we move deeper into the tree, the chance that some node at each level will not drop the message can be quite high, so our message has a high probability of traveling forever. For example, if 100 nodes at a given tree level flip independent, fair coins that cause each node to drop a message 50% of the time, then we expect 50 of the nodes at this level to keep passing the message---if they each forward to 4 neighbors, then our next tree level has 200 nodes. The following image shows a flood tree in which each node has a 50% chance of dropping a message and a 50% chance of sending it on to 4 neighbors. Red nodes have chosen to drop the message, and green nodes have decided to pass it on.
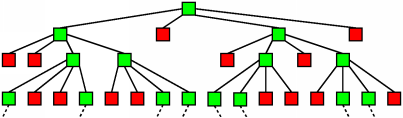
Notice that the number of green nodes doubles at each successively deeper tree level---the message will be likely to travel forever.
What happens if their probability computations are not independent? The idea is to pass a random number generator along with each message and have nodes manipulate the state of the random number generator as they decide to forward or drop a message. A node will forward the same generator with the same state on to each of its neighbors, so the neighbors will all make the same decision about whether to forward or drop the message. Thus, we have all nodes at a given tree level making the same probability computation. We end up with a tree of random depth, which is essentially what we want: we can be certain that the message will be dropped eventually instead of traveling forever.
Our hybrid approach involves starting each search as a random-depth flood, as described above, with each node manipulating a random number generator that is attached to the search query. During the random-depth flood portion of a query's life, the UC is left at the starting value of 0. Once a particular result comes out of the random number generator (what we will call a trigger value), the message changes modes into a UC-limited flood, which we described earlier. Thus, a message travels for a random number of hops with no UC limits, then travels further with UC limits.
How does this mechanism protect sender anonymity? The sender initializes the state of the random number generator before sending a search. By simulating the future manipulations that other nodes will perform on the random number generator, the sender could figure out how far the message will go before switching into UC mode. However, neighbors of the sender simply see a random number generator with a particular state, and there is no way for them to detect that their neighbor created this generator state. The sender's neighbors can also run simulations on the number generator to figure out how much farther the message will go before switching modes, but this simulation gives them no information about how far the message has traveled so far, as long as the random number generator's previous states cannot be determined from its current state.
To implement such a random number generator, we use a 20-byte SHA1 hash value as the generator state and attach such a value to each search query. To generate a new random value from the generator, a node simply re-hashes the current hash value, which generates another hash. A trigger value can be taken from the last few digits of the hash. For example, to switch message modes with a 1 in 5 chance, we could look at the last byte of the newly-generated hash and switch modes if the last byte is less than or equal to 51 (there are 256 possible values for the last byte). SHA1 is a cryptographically secure one-way function, so it is very difficult to obtain previous generator states from the current state, and thus it is difficult to determine how far a message has traveled so far.
Our random depth flooding mechanism, as described so far, still suffers from a statistical vulnerability. If each search from a given node uses a different random depth flood, then searches generated by an immediate neighbor will have different statistical properties than searches generated by more distant nodes: if a series of searches is generated by a neighbor, we will always be part of the random flood, but if the searches are generated by a more distant node, the random flood will sometimes be over by the time the search reaches us. To prevent this kind of statistical analysis from being performed by an attacker across multiple searches, we must use the same starting generator state repeatedly for each search request that a given node sends. Thus, a given node always starts a search with the same a flood depth, though this depth cannot be determined by other nodes. Since the same depth flood is used for each search, we will always be part of the flood or always not be part of the flood, independent of whether the sender is our neighbor.
10. Ensuring Search Responder Anonymity
The above scheme ensures that an attacker cannot easily determine the origin of a search request, but it does nothing to guarantee the anonymity of nodes that are responding with search results.For example, to determine what files an immediate neighbor is sharing, an attacker could send a search request with an artificially high UC. With a properly chosen UC, the attacker could trick the neighbor into sending back its own results but not passing the message further.
No deterministic dropping scheme can be used to protect responder anonymity. An attacker can simulate a deterministic scheme ahead of time and find a drop mechanism value that would force its neighbor to process and drop a message. For example, we might try to use the random generator scheme described above to anonymize the tail of the search: once the UC limit is hit, the message could again switch into random-flood mode for a few additional hops. However, an attacker could pick an appropriate SHA1 hash value that would hit the trigger value after only one rehashing and trick its neighbor into dropping the message.
Thus, we need a truly probabilistic scheme in which each node makes an independent probability calculation---an attacker could not manipulate such calculations.
Though probabilistic limiting schemes do not work for branching message paths, they do work for non-branching paths (chains). For example, if each node in a chain has a 50% chance of dropping a message, then we expect the message to travel 2 hops on average, and the probability of a message traveling forever along the chain is effectively 0. Thus, once a message has hit its UC limit, we switch it into a chain mode and send it a few more hops. Each node in the chain has some probability of breaking the chain and dropping the message completely.
In this scheme, each node that receives a chain-mode message essentially flips a weighted coin. When a node flips heads, it picks one neighbor to send the message to and continues the chain. If a node flips tails, it drops the message. Increasing the probability of heads increases the expect length of the chain and also increases responder anonymity.
An attacker has no way to force its neighbor to be the only node that sends back results, since it has no way to control how many nodes beyond its neighbor will process the message. For example, if the attacker sends a message with an artificially high UC, the neighbor will switch the message into chain mode, and the message will still travel through additional nodes before being dropped. Each of these additional nodes might be sending back results, so any results that the attacker receives cannot be associated with the neighbor node.
This scheme falls victim to the same kind of statistical analysis that we mentioned in the previous section. If the tail lengths are determined by flipping independent coins at each hop, we expect more length-1 tails than length-2 tails. An attacker can send searches repeatedly into a tail and measure the frequency of various search results. The most frequent results must be coming from the length-1 tails, so they must be from the attacker's neighbor. To thwart this kind of analysis, we need to ensure that the each particular tail is always the same length, though we must prevent the attacker from determining or influencing that length. Each node, upon startup, decides randomly whether it will drop tail chain messages or pass them on, and it behaves the same way for every tail chain message that it receives. Each node also picks one neighbor and, if it passes tail chain messages, always passes them through that neighbor, as long as that neighbor remains connected. Thus, for a given neighbor, tail chains that we pass through that neighbor will always be the same length, and we will have no way of knowing how long the chains are. Tail lengths will change slowly over time as the network topology evolves, but gathering meaningful statistical information from the resulting tail lengths will be difficult, especially since an attacker has no information about how the topology beyond a given neighbor node is changing.
The following image shows a distribution tree that uses both anonymizing schemes. The green nodes are passing the message in random-flood mode, which continues for two hops in the tree. The magenta nodes are passing the message in UC mode, adding to the UC at each hop depending on the number of results generated and the branching factor. Once the UC limit is hit, the message switches into chain mode. Each blue node either passes or drops all chain-mode messages that it receives, so each chain eventually reaches a drop-node and ends.
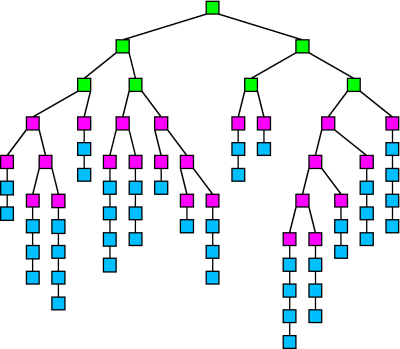
10.1 A Possible Attack
The tail chain mechanism for ensuring responder anonymity will work to thwart a single attacker, even if the attacker is neighbors with the node being attacked. There is no way for such an attacker to send a node a search message that forces the node to be the only node sending back results. Even if only one set of results returns to the attacker, the attacker cannot be sure that the results came from the neighbor node or from further down the tail chain. A node can plausibly deny that it was the one sending back the results that the attacker sees.What happens if multiple attackers work together? Obviously, as discussed elsewhere, if a node is completely surrounded by cooperating attackers, we have no hope of maintaining that node's anonymity---the attackers can monitor all traffic going in and out of the node and easily determine which search results are being generated by the node. As long as a node has one or more neighbors that are not attackers, the node should be able to plausibly deny sending back particular search results. Because the attackers cannot see the internal state of the node being attacked, they can never be sure that they have indeed surrounded the node---the node could have an extra non-attacker neighbor that they are not aware of.
But during the tail-chain part of a search flood, nodes only send the request on to at most one of their neighbors. An attacker could compose a fake search request that instantly enters tail-chain mode (by falsely setting a high UC for the message) and send it to our node. We would send back results and send the tail-chain message on to one of our neighbors. If the chosen neighbor is also controlled by the attacker, the two attacking nodes have effectively cornered our node: Attacker A has sent a tail-chain message to us and gotten results back from us, while attacker B has received our forwarded tail-chain. If attacker B kills the tail-chain message, then A can be sure that the results it sees are coming from us. The following picture shows the attackers A and B in the context of a tail chain, which is shown in blue:
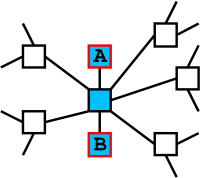
The success of this attack does not depend on the attackers knowing that they have surrounded us---indeed, they do not need to surround us at all. Of course, the attackers need to be lucky in order to succeed---most of the time, we will not pick the second attacker as the node that we will send all tail-chain messages to. However, if a pair of attackers tries long enough, they will eventually connect to a node that picks the second attacker as the node to which tail-chain messages will be sent. Thus, though the tail-chain mechanism can protect search responders in the face of a single attacking node, it will not work against pairs of nodes that are working together.
10.2 Thwarting the Attack
The weakness exploited by the above attack is this: if we are responding to a tail-chain search request and sending it onward, we are always sending it to only one neighbor. The attackers know this fact about tail chains, and they can exploit this knowledge to corner us (if we happen to send a tail-chain message onward to an attacker, the attackers know that we have not sent it on to any other neighbors---whatever results they receive must be coming from us). When cornered in this way, we have no room to claim plausible deniability.To thwart this attack, we need to introduce more doubt. With tail chains, there is doubt about whether we will send a request onward or not, but there is no doubt about how many neighbors we will send the request to. Thus, we need a mechanism that makes an attacker unsure about how many neighbors we send a tail message on to.
Of course, we need to be careful about branching factors here: if our mechanism causes most nodes to send tail messages on to two or more nodes, the message will travel forever in the network and never be dropped completely (the number of nodes receiving the tail message would double at each hop in the tail).
With our original, non-branching tail chains, we need at least one node per chain that has decided to drop tail-chain messages. This node serves as the terminating node at the end of the chain to ensure that the chain does not go on forever. So, for each chain at the end of the distribution tree, we need a drop-node at the end of that chain.
If we introduce some branching into the tail portion of the flood, we are effectively multiplying chains. If a node sends a tail message on to two neighbors, it converts one chain into two chains (we will call such a node a 2-node). Likewise, if a node sends a message on to three neighbors, it converts one chain into three chains (such a node is called a 3-node). A node that sends a tail message on to i neighbors is called an i-node and converts one chain into i chains.
Thus, for each node that multiplies chains through branching, we need extra drop-nodes somewhere in the network to terminate these chains. For example, if we have a 3-node in the tail of our flood, we will need 2 extra drop-nodes. Thus, if we have a network of 10 nodes that contains a 3-node and a 2-node, we will need at least four drop-nodes (one for the chain that we start out with, two for the chains created by the 3-node, and one for the chain created by the 2-node). The rest of the nodes can be 1-nodes that forward chains without branching. Notice that these 10 nodes can be arranged in a tree as follows:
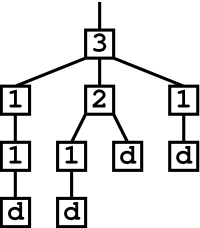
If we want to assign each node in our network a behavior for tail messages, we need to do so in a way that will allow the nodes to be theoretically assembled into this kind of tree with drop-nodes at the leaves. If it is not possible for the nodes to be arranged in such a tree, we do not have enough drop-nodes. For example, if we replace one of our drop-nodes in our 10-node network with a 1-node, we cannot build a proper tree---our tree needs four leaves because of the branches created by the 2-node and the 3-node, but we would only have 3 drop-nodes to use as leaves.
In the above picture, we started out with only one chain, so we needed one extra drop-node in addition to those needed to terminate chains created by our 2- and 3-nodes (four drop-nodes total). However, if we started out with three chains, we would need drop-nodes for each of these chains in addition to drop-nodes to terminate the chains created by our 2- and 3-nodes, so we would need a total 6 drop-nodes, as shown below:
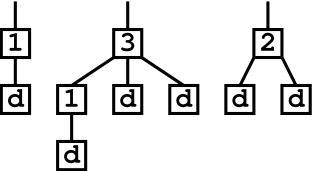
In practice, we always start with many chains at the beginning of a flood tail. In the worst case, each of our i-nodes could be part of separate chains, an we would need an extra drop-node for each i-node in addition to the (i-1) drop-nodes needed to terminate the chains created by each i-node.
How many total drop-nodes do we need to handle the worst case? At least enough to "cover" all of the chains created by 2-, 3-, 4-, ... and i-nodes, plus an extra drop-node for each of these nodes (including an extra node for each 1-node). Thus, for an i-node, we need at least i drop-nodes to cover it in the worst case. Let c(i) be the number of i-nodes in our network (so c(2) would be the number of 2-nodes, and c(drop) would be the number of drop-nodes). we would need:
| c(drop) >= c(1) + 2 c(2) + 3 c(3) + 4 c(4) + 5 c(5) + ... + i c(i) + ... | (constraint 1) |
In other words, we have at least enough drop nodes to cover all chains in the network. Also, we have the constraint that
| N = c(drop) + c(1) + c(2) + c(3) + c(4) + ... + c(i) + ... | (constraint 2) |
where N is the total number of nodes in our network. In other words, every node picks a behavior type, and the numbers of nodes picking each type can be summed to equal the number of nodes in the entire network.
We want to convert these constraints into a probability distribution that each node can use to independently select its tail message behavior. We want p(i) to be the probability that a given node decides to be an i-node. We can do this conversion by dividing each count, c(i), by the total number of nodes in the network. Thus, p(i) = c(i)/N. Applying this idea to our second constraint from above, we can divide through by N to get :
So our second constraint forces us to have a proper probability distribution (the probabilities sum to 1). Dividing our first constraint through by N, we get:
In other words, the probability of being a drop-node must be at least as large as the probabilities of being the other node types combined.
One way to satisfy the constraints is to let p(drop) = 3/4 and let
With this formulation, the sum of (i * p(i)) for i=1 to infinity is equal to 1/2, so it is less than or equal to p(drop) as required by our first constraint. The sum of p(i) for i=1 to infinity is equal to 1/4, and added to p(drop), is equal to 1, satisfying our second constraint.
In the above formulation, our first constraint is satisfied by loose inequality, with p(drop) being larger than it needs to be. There is a solution that satisfies our first constraint with exact equality: we can let p(drop) = 2/3 and let
The probabilities p(i) then sum to 1/3, while the (i * p(i)) quantities sum to 2/3. This formulation will result in messages traveling farther before being dropped. In addition, the probabilities are fractions with denominators that are multiples of three---powers of two are more familiar and thus easier to manipulate and reason about. We will use the looser formulation below, with p(i) = 1 / ( 2^(i+2) ), below.
We can generate a table of the resulting probabilities:
|
Number of neighbors we send tail messages to: |
Probability of picking this behavior on startup: |
| 0 (drop) | 3/4 |
| 1 | 1/8 |
| 2 | 1/16 |
| 3 | 1/32 |
| 4 | 1/64 |
| 5 | 1/128 |
| 6 | 1/256 |
| 7 | 1/512 |
| . . . | |
To avoid messages that travel forever, we need an expectation that is less than 1, and our formulation satisfies this requirement. Many simple probability distributions will have expectations less that one. For example, if 3/4 of the nodes send to 0 neighbors and 1/4 of the nodes send to 2 neighbors, our expected number of neighbors is again 1/2. However, such simple distributions do not introduce enough doubt: if we either send to 0 neighbors or 2 neighbors, then 3 attackers can corner us. There needs to be a non-zero probability of sending to any number of neighbors, and our distribution achieves this.
Returning for a moment to our tighter formulation, we get an expectation of 2/3. Thus, at each hop in the tail of the flood, the number of nodes is reduced by a factor of 1/3, though this drop-out factor is less sever that the factor of 1/2 from our looser formulation. This agrees with our earlier analysis: the tighter formulation will allow messages to travel farther.
For the original non-branching tail chains, each node decided randomly at startup whether it will pass or drop messages that are in tail mode---if it passes tail-mode messages, it passes them to one neighbor. This prevented an attacker from sending a series of messages to a node and using statistical analysis, since all of the messages in the series would travel the same distance (repeated sampling by sending multiple messages reveals nothing). Of course, tail chains could only thwart a 1-neighbor attack.
To thwart an (n-1)-neighbor attack, where n is the number of neighbors that we have, we can decide at startup, using the above probabilities, how many neighbors we will pass tail-mode messages to, and we will always pass them to the same set of neighbors as long as those neighbors are connected. Thus, though an attacker might send us a search request in tail mode, and though some of the cooperating attackers may receive some of the forwarded tail-mode messages that we send (since they may be the neighbors that we have selected to receive our tail-mode messages), they cannot be certain that we are not also forwarding the search request on to other neighbors.
Even if 9 attackers surround us and 8 of them get forwarded tail-mode messages from us, they cannot be sure that we are not sending tail-mode messages to 9 neighbors, one of which is not an attacker.
10.3 An Example
At the end of our description of tail chains, we showed a tree with 16 blue tail chains. We can replace these chains with branching tails using our formulation. Applying our probability distribution to the first 16 tail nodes, we get the following rough expected numbers:|
Number of neighbors we send tail messages to: |
Number of nodes picking this behavior on startup: |
| 0 (drop) | 12 |
| 1 | 2 |
| 2 | 1 |
| 3 | 1 |
| 4 | 0 |
| . . . | |
|
Number of neighbors we send tail messages to: |
Number of nodes picking this behavior on startup: |
| 0 (drop) | 5 |
| 1 | 1 |
| 2 | 1 |
| 3 | 0 |
| . . . | |
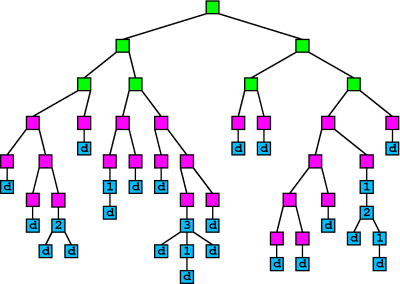
10.4 Another Possible Attack
There are two different kinds of search-related attacks that threaten anonymity. First, we have attacks that are aimed at discovering what a given node is searching for. The random-flood mechanism described in section 9 above effectively thwarts this attack, even if several attackers are working together. Second, we have attacks that are aimed at discovering what search results a given node is returning.If one attacker is working alone, the UC portion of the flood can reveal nothing about what results a neighbor is returning. The tail chain mechanism would prevent an attacker from forcing its neighbor to be the last node to send back results. However, multiple attackers, working together, can exploit the structure of tail chains to determine what results a node is sending back. The new tail tree mechanism can thwart such a group attack by randomizing the structure of the tail so that it cannot be exploited.
The UC portion of the flood (marked with magenta in the above diagrams) is itself vulnerable to multi-neighbor attacks similar to those that threatened tail chain anonymity. UCs are updated by each node in a way that reflects how many results that node is returning (see section 7.1 above). Two attacking neighbors can cooperate to observe how much a node adds to the UC of a message before passing it on (one attacker sends a search request with a low UC, and the other attacker observes the forwarded copy of the message with th the updated UC).
Though knowledge of our UC update will not reveal exactly how many results we are returning (since the UC update also depends on how many neighbors we have), it will tell the attackers whether or not we are returning results in many cases. For example, say that we have 100 results and 5 neighbors (and let the UC update parameters be alpha=1, beta=1, gamma=0). Then we would add 105 to the UC before passing the message on. We certainly cannot claim that we have 105 neighbors, so we are certainly sending back some results. If we are the only node that sends results back for this query, the attackers can be sure that these results came from us.
Our only hope in thwarting all multi-neighbor analysis attacks is to update UCs in a way that reveals nothing about the state of our node. Unfortunately, both key components of the UC update formula are revealing: the first component is based on how many results we return, while the second component is based on how many neighbors we have. Our plausible deniability defenses against being surrounded by neighbors that are all attackers involve claiming that we have an extra neighbor that the attackers do not know about. Thus, our neighbor count is actually critical information that must be kept private.
For the sake of anonymity, we must revert to the UC parameter set [alpha=0; beta=0; gamma=1], which causes UCs to emulate TTLs. Thus, every node will increment the UC of a message before passing it on, revealing nothing about its private state. Incorporating information about result and neighbor counts in the UC update formula improves scalability dramatically and would be very helpful in a non-anonymous setting. Unfortunately, we cannot take advantage of these scalability gains without putting the anonymity of search responders at risk.
Thus, we end up with a rather standard flooding scheme (TTL) sandwiched between two anonymizing mechanisms (random-depth floods and tail trees). In our pictures, we have a magenta layer in the tree between a green and blue layer. This seems overly-complicated, and we might want to completely replace the standard, deterministic flooding with some other mechanism that preserves anonymity by itself. If we could devise such a mechanism, we would remove the need for three separate control modes in our anonymous search.
However, some deterministic exponential distribution scheme (such as TTLs) is necessary to ensure that messages reach a sufficient portion of the network. We could not use random-structured trees (like we do in the tail) for the body of the search and achieve a thorough, dependable search of a large collection of nodes. For example, if the number of nodes was cut in half at each step in the body of the flood, and we started out sending to our 6 neighbors, the flood would only reach 10 nodes. The cut-off in these deterministic schemes (a TTL of 0, or a UC that is larger than the limit) ensure that the entire network is not flooded---we want our search to reach a large collection of nodes, but not to reach the entire network. A random-depth flood mechanism at the head, along with random trees at the tail, can make such a deterministic flood mechanism safe for use in an anonymous network, but it is the deterministic, limited-exponential body that does most of the searching work.